
Over time, Salesforce environments are prone to “field bloat”. Fields are added to Salesforce objects to support business processes, automation, and reporting needs, among others. In many cases the need for these fields is temporary.
Time marches on, however, and more and more fields get added to Salesforce - complicating administration and reporting, and confusing both administrators and users. Administrators are hesitant to ever remove fields - often fields predate the administrator joining the team, they don’t know why they are there or how they are used, and they fear that removing them will break reporting or automation and cause serious issues.
Salesforce recognizes this problem, and has started to roll out features to address it:
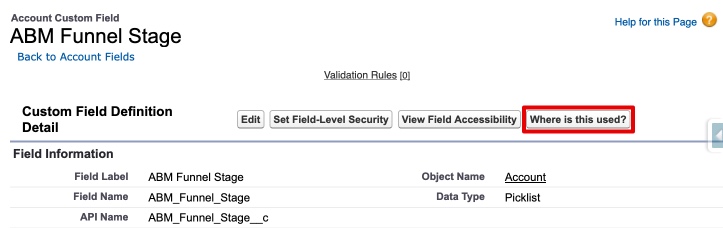
Information on “Where is this used?” can be found here.
This feature does have some limitations - two significant ones are:
- It is only available for custom fields. So, for example, if you want to change your Opportunity Stages, and are worried that old values might be hard-coded somehwere, this feature can’t help you.
- If you have multiple fields to check, they have to be done one at a time.
Until Salesforce’s features in this area get more mature, I wanted to offer another approach that I have used with clients in the past.
Another Solution
This solution uses an simple ruby script that uses grep and the nokogiri XML parsing gem to search a copy of a Salesforce environment’s extracted metadata for references to a set of fields provided to the script in a CSV file. The output of the script is another CSV file, highlighting all of the matches.
The script below makes the following assumptions:
- The nokogiri gem is installed
- there exists a folder
metadataat the same level as the script file, containing the metadata extracted from Salesforce - there exists a file
fields.csv, that is a one-column CSV file consisting of the API names of the fields of interest. The column heading is “field”
Please note that there are some nuances to using this script. For example, if you want to search for impacts to the Opportunity RecordTypeId field, you are invariably going to get results that refer to that same field on other objects. I have not dug in to see how I might solve this problem - perhaps an exercise for the reader?
require 'csv'
require 'nokogiri'
fields = []
CSV.foreach('fields.csv', headers: true, header_converters: :symbol) do |row|
fields.push(row[:field])
end
results = []
fields.each do |field|
status_message = "Processing #{field}"
(79 - field.length).times { status_message += '.' }
puts status_message
# Reports
result = `grep -irl #{field} ./metadata/reports`
result.split(/\n/).each { |item| results.push(field: field, type: 'Report', name: item) }
# Report Types
result = `grep -irl #{field} ./metadata/reportTypes`
result.split(/\n/).each { |item| results.push(field: field, type: 'Report Type', name: item) }
# Dashboards
result = `grep -irl #{field} ./metadata/dashboards`
result.split(/\n/).each { |item| results.push(field: field, type: 'Dashboard', name: item) }
# Home Page components
result = `grep -irl #{field} ./metadata/homePageComponents`
result.split(/\n/).each { |item| results.push(field: field, type: 'Home Page Component', name: item) }
# Home Page Layouts
result = `grep -irl #{field} ./metadata/homePageLayouts`
result.split(/\n/).each { |item| results.push(field: field, type: 'Home Page Layouts', name: item) }
# Layouts
result = `grep -irl #{field} ./metadata/layouts`
result.split(/\n/).each { |item| results.push(field: field, type: 'Layout', name: item) }
# Custom Metadata
result = `grep -irl #{field} ./metadata/customMetadata`
result.split(/\n/).each { |item| results.push(field: field, type: 'Custom Metadata', name: item) }
# Flows
result = `grep -irl #{field} ./metadata/flows`
result.split(/\n/).each { |item| results.push(field: field, type: 'Flow', name: item) }
# Email
result = `grep -irl #{field} ./metadata/email`
result.split(/\n/).each { |item| results.push(field: field, type: 'Email', name: item) }
# Triggers
result = `grep -irl #{field} ./metadata/triggers`
result.split(/\n/).each { |item| results.push(field: field, type: 'Apex Trigger', name: item) }
# Classes
result = `grep -irl #{field} ./metadata/classes`
result.split(/\n/).each { |item| results.push(field: field, type: 'Apex Class', name: item) }
# VF Pages
result = `grep -irl #{field} ./metadata/pages`
result.split(/\n/).each { |item| results.push(field: field, type: 'Visualforce Page', name: item) }
# VF Components
result = `grep -irl #{field} ./metadata/components`
result.split(/\n/).each { |item| results.push(field: field, type: 'Visualforce Component', name: item) }
# Lightning Web Components
result = `grep -irl #{field} ./metadata/lwc`
result.split(/\n/).each { |item| results.push(field: field, type: 'Lightning Web Component', name: item) }
# Lightning Components
result = `grep -irl #{field} ./metadata/aura`
result.split(/\n/).each { |item| results.push(field: field, type: 'Lightning Component', name: item) }
# Lightning Record Pages
result = `grep -irl #{field} ./metadata/flexipages`
result.split(/\n/).each { |item| results.push(field: field, type: 'Lightning Page', name: item) }
# Snapshots
result = `grep -irl #{field} ./metadata/analyticSnapshots`
result.split(/\n/).each { |item| results.push(field: field, type: 'Reporting Snapshot', name: item) }
# Workflow Rules
result = `grep -irl #{field} ./metadata/workflows`
result.split(/\n/).each do |file|
wf_doc = Nokogiri::XML(File.read(file))
wffu_nodeset = wf_doc.xpath('//sf:fieldUpdates', 'sf' => 'http://soap.sforce.com/2006/04/metadata')
wffu_nodeset.each do |wffu|
field_match = false
wffu.traverse { |item| field_match = true if item.name == 'field' && item.inner_text.downcase.include?(field.downcase) }
if field_match
wffu.traverse { |item| results.push(field: field, type: "#{file} :: Field Update", name: item.inner_text) if item.name == 'fullName' }
end
end
wfr_nodeset = wf_doc.xpath('//sf:rules', 'sf' => 'http://soap.sforce.com/2006/04/metadata')
wfr_nodeset.each do |wfr|
field_match = false
wfr.traverse { |item| field_match = true if item.name == 'formula' && item.inner_text.downcase.include?(field.downcase) }
if field_match
wfr.traverse { |item| results.push(field: field, type: "#{file} :: Rule", name: item.inner_text) if item.name == 'fullName' }
end
end
end
# Validation Rules
result = `grep -irl #{field} ./metadata/objects`
result.split(/\n/).each do |file|
obj_doc = Nokogiri::XML(File.read(file))
vr_nodeset = obj_doc.xpath('//sf:validationRules', 'sf' => 'http://soap.sforce.com/2006/04/metadata')
vr_nodeset.each do |vr|
field_match = false
vr.traverse { |item| field_match = true if item.name == 'errorConditionFormula' && item.inner_text.include?(field) }
if field_match
vr.traverse { |item| results.push(field: field, type: "#{file}: Validation Rule", name: item.inner_text) if item.name == 'fullName' }
end
end
end
# Filter Fields
result = `grep -irl #{field} ./metadata/objects`
result.split(/\n/).each do |file|
obj_doc = Nokogiri::XML(File.read(file))
fi_nodeset = obj_doc.xpath("//sf:fields[sf:lookupFilter/sf:filterItems/sf:field='#{field}']", 'sf' => 'http://soap.sforce.com/2006/04/metadata')
fi_nodeset.each do |fi|
results.push(field: field, type: "#{file}: Filter Field", name: fi.first_element_child.inner_text)
end
end
# Sharing Rules
result = `grep -irl #{field} ./metadata/sharingRules`
result.split(/\n/).each do |file|
obj_doc = Nokogiri::XML(File.read(file))
sr_nodeset = obj_doc.xpath("//sf:sharingCriteriaRules[sf:criteriaItems/sf:field='#{field}']", 'sf' => 'http://soap.sforce.com/2006/04/metadata')
sr_nodeset.each do |sr|
results.push(field: field, type: "#{file}: Sharing Rule", name: sr.xpath('.//sf:label', 'sf' => 'http://soap.sforce.com/2006/04/metadata')[0].inner_text)
end
end
end
CSV.open('output.csv', 'wb') do |csv|
keys = %i[field type name]
csv << keys
results.each do |hash|
csv << hash.values_at(*keys)
end
end
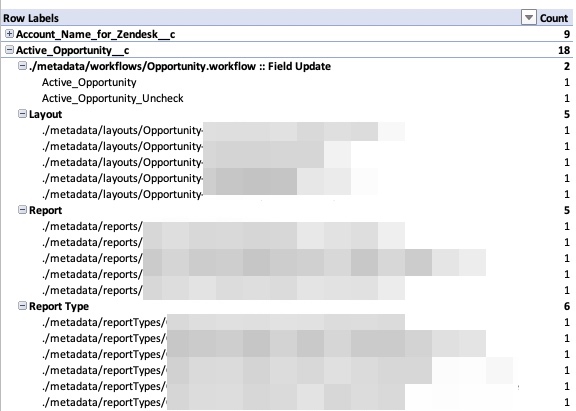
The Results
The resulting CSV can be pulled into Excel, where you can construct some nice Pivot Tables to review the data:
Conclusion
Hopefully you can use this or a similar solution to give yourself the confidence to remove unused fields from your Salesforce environment - lots of goodness flows from having an orderly, streamlined application with a minimum of unnecessary parts!