
I recently pitched in on a project to identify likely duplicates in a file of about 100,000 customer records, in preparation for loading them into Salesforce.
The data was fairly messy - with lots of near-duplicates. I set out looking for the easiest technical path to identify likely dupes in the file using some form of fuzzy matching. This seemed like a great use case for machine learning, and with the huge recent growth in that field, I wondered if there were any ML tools that could be easily applied to this problem.
Developing the fast, effective approach for customer record de-duplication is a worthwhile pursuit given the ubiquity of duplicate data in CRM databases, and the tax they put on user productivity. I don’t claim to have found the “best” yet, but I wanted to share an interesting tool that I came across and ended up using for this task:
Csvdedupe
Csvdedupe is a command-line utility for de-duping CSV files, built on the dedupe python library. Full information on the tool is available at GitHub and at this site.
The tool is very easy to use, and fairly fast. Once installed, you run it from the command line, and pass it your CSV file of data, and an option or configuration file to tell it which columns to consider when looking for duplicates.
Then the machine learning magic kicks in - the tool prompts you with a series of record pairs for you to evaluate and mark as duplicates/not duplicates/unsure:
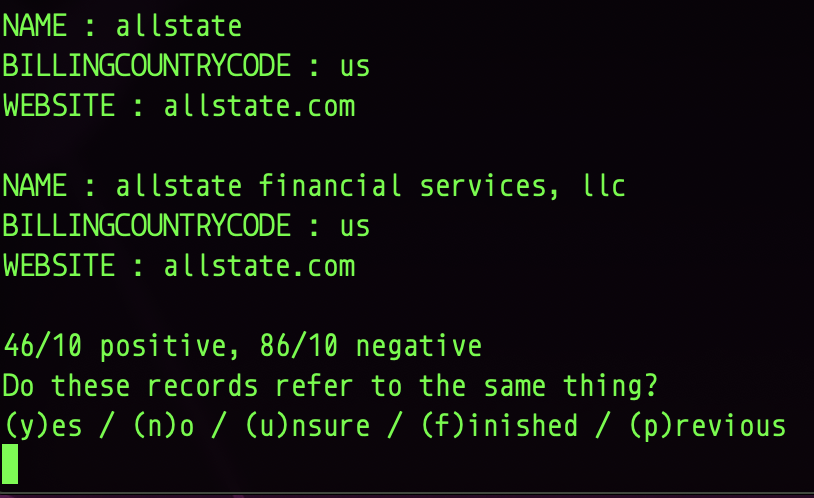
This is the training phase, and you can go on as long as you would like ( I think I ran through about 40 pairs). Once you finish training, the tool goes to work on the full file, and returns an output file with new “Cluster Id” column added, listing the duplicate group that each record belongs to.
The results were very good - especially given the small number of fields I gave the tool to work with, and the limited patience I had for evaluating test pairs.
Small gotchas:
- Python is not in the PATH on my Mac, so I needed to invoke csvdedupe using the full path:
/User/<username>/Library/Pyton/2.7/bin/csvdedupe - Csvdedupe seemed to choke on non-ascii characters in my dataset, so I ended up stripping them out. I have some concerns about the impact this might have on the matching - something to dig into at a later time.
Another interesting project I discovered during this research is called Duke - it looked like a bigger lift to get going than csvdedupe (a pretty low bar), so I have not dug into it yet.
Happy de-duping!