
I worked on an interesting problem for a client recently, and I thought I would take a moment to share some of the learnings in case they are helpful to anyone else.
The client was implementing a named-accounts sales territory plan, and want a tool to help them create groups of Accounts that will make up the territories, from the 150,000 unassigned Accounts in their Salesforce instance. They want to apply some constraints on these groups – they should consist of between x and y Accounts, for example, and the distance between any two Accounts in the group should not exceed z (so that the driving required for the salesperson is manageable). Once these groups have been identified, the client would like to be able to download them to Microsoft Excel for further analysis, and potentially future upload back into Salesforce.
So how best to develop such a tool with Salesforce?
Solution
I initially thought of clustering algorithms, and reviewed several implementations of these for geographic data – including k-means and DBSCAN. I also reviewed the “hierarchal greedy clustering” approach used by a library called “supercluster”, developed by the Mapbox team. The challenge I encountered was how to cleanly apply the prospect’s constraints. Some of the algorithms expected you to provide a number of clusters as an input (not what I was after) – others seemed to yield clusters that would violate the distance constraint. Eventually I came across a very useful javascript library called geokdbush – and decided to use it roll my own solution, working roughly along the same lines as the supercluster approach.
Geokdbush adds a geographic twist to another library, kdbush, which is a spatial index. Both libraries were created by Vladimir Agafonkin, an engineer at Mapbox. Once you load all of your locations(Accounts) into the index, it can be used to rapidly perform geographic queries like “what is the distance between location A and B?” or, more usefully for this application, “what locations are closest to location A?”.
I used browserify to prepare a javascript file including the necessary libraries, and loaded it into my Salesforce environment as a static resource.
Identifying Groups by Querying the Spatial Index
One the index of locations(Accounts) is built, the solution logic is as follows:
- Select an “unprocessed’ Account record, designated as the “base”
- Query the index for the list of Accounts (up to the maximum group size) that are within the defined radius from the base, using the geokdbush around function.
- If the resulting list is larger than the minimum group size, flag the entire set (including the base) as a new group, and mark them all as processed.
- If the resulting list is smaller than the minimum group size, flag just the base as processed.
- Repeat until all Accounts are marked processed
Testing the solution was initially challenging – Salesforce developer edition instances are storage constrained, and you can’t just load one up with 150,000 Account records. For initial testing, I ended up first generating random locations in the page script – but grew concerned that this data was not sufficiently realistic, as real Accounts are not spread uniformly across the country. A few minutes and a few Google searches later, I had a data set of 102,687 public school locations in the United States. These map roughly to population, and yield a much better data set for sampling. I loaded these records into the page for testing. The results were encouraging – the solution was able to build groups from the school dataset of 102,687 records in a minute or two.
In reviewing the prototype with the prospect, they raised an interesting follow-up question. There are multiple “solutions” to the grouping problem, based on which Account record the logic starts with, and which unprocessed Account it processes next each time through the loop. Can the solution be optimized to maximize the number of groups identified?
Before tackling the prospect of optimizing the logic, I decided to conduct a bit more research. Some questions I was curious about were: (a) how efficient is the grouping (e.g. how many of the total records end up in groups? and (b) how much variability is there in the grouping? If I were to feed the locations into the code several times, shuffling the locations each time, how different would the results be?
Some quick testing indicated the answers – (a) the grouping seems efficient – about 90% of the locations are grouped when you set group size of between 50 and 70 Accounts, and a group radius of 40 miles, and (b) there was little variability in the results over multiple runs of the code. Given the high rate of grouping and the low variability, it seems feasible to table the question of optimization.
Polishing Things Up…
To round out the solution, I added features to output the results of the grouping to a CSV file, using the Papa Parse CSV library.
And I added a Leaflet map to show the group locations (dropping a marker on the centroid of each group). The final interface looks as follows:
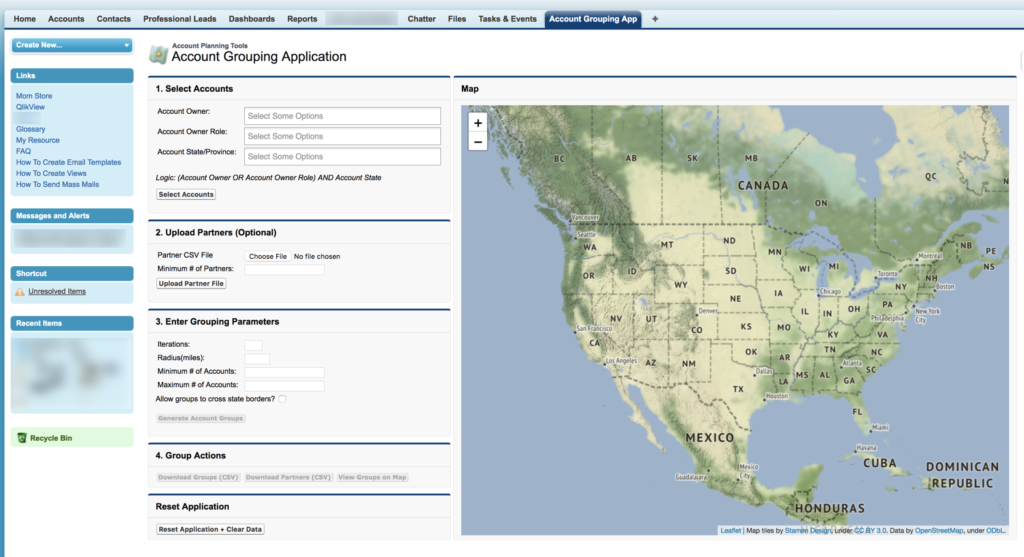
Summary
So more fun with geographic data! Hope you enjoyed this post – if nothing else, you are now aware of the fantastic geokdbush library (if you weren’t already) – hopefully it can help you with your projects involving geographic data.